Enjoy your Turkish coffee
while we process your Turkish text
Enjoy your Turkish coffee
while we process your Turkish text
The fastest way to build solutions that necessitates Turkish text processing. Middleware for Turkish Natural Language Processing
Text Normalization
Users generate improper words, we fix them for better text analysis.
Frequently, user generated content involves lots of misspellings, abbreviations, intentionally broken words and similar issues which block accurate text analysis. Thanks to our complicated models, each token is normalized and transformed to its canonical form, which enables better analysis results.
Read More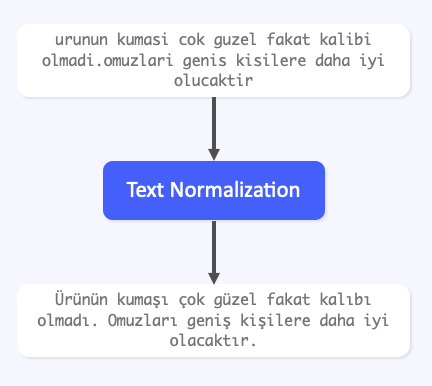
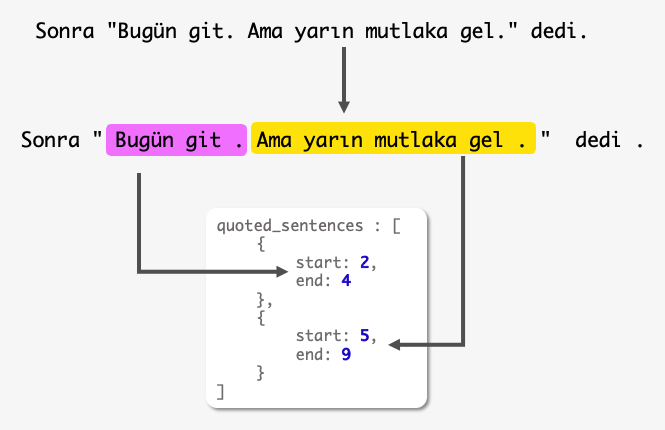
Advanced Tokenization
Are you tired of improper tokenizations?
Being the very first step in an NLP pipeline, tokenization plays a key role to minimize error propagation. Our tokenization module is tailored for the best performance on Turkish. Going beyond regular sentence splitting, it is even capable of sub-sentence segmentation in quotation marks. A vivid word boundary detector can capture the most compelling tokens in the sentences.
Read MoreFine-Grained Entities
Basic PERSON, ORGANIZATION and LOCATION named entity types are not enough for you?
Our fine-grained Named Entity Recognizer (NER) is trained to capture 21 different types of entities by the help of our deep learning models.
Read More
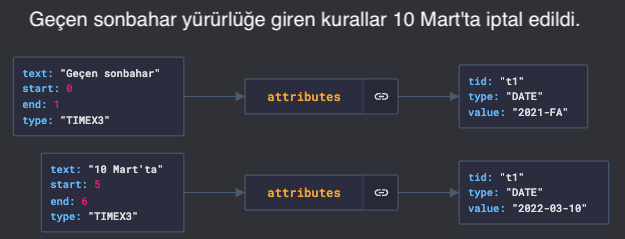
Temporal Expressions
Timing is everything. But, are you sure you capture the temporal information correctly?
We offer a wide coverage temporal expression identifier and normalizer, supporting TIMEX3 standard. Both absolute (such as 19 Haziran) and relative (such as geçen sonbahar ) experssions are supported.
Read MoreMorphology
Get the lemma of each wordform along with all morphological tags.
We provide a full-fledged morphological analysis on every token and solve the morphological ambiguities to provide you the correct lemma and morphological structures according to the context.
Read More
Syntax
Discover the relationships between the words in a sentence.
A deep learning based parser allows you to get the syntactic relationships and dependencies among the words in the sentence. Thanks to this syntactical analysis, deeper NLP analysis may be implemented more accurately.
Read MoreSentiment
Are you interested in the aspects and their sentiments in the text?
Determining the sentiment of the text based on aspects is very easy with our wide spectrum aspect based sentiment analysis.
Read More

Continuous Improvement
Human languages are extremely complex and ambiguous. Although recent advances in NLP field led stunning results, there are lots of things that must be improved.
We constantly work hard on improving the performance of our NLP components, with a particular focus on Turkish. The diligent efforts of our experienced staff turn the outputs of our academic research studies into industry level, robust NLP services that power up real world applications.
Browse Our PublicationsNeed Custom Solutions?
We appreciate the value of in-domain data. Let's work together if you require higher accuracy beyond our general-purpose API.
You can still use our cloud API with your custom trained models or opt for on-premise solutions.
LEARN MORE